What is pageInspector?
Functionalities
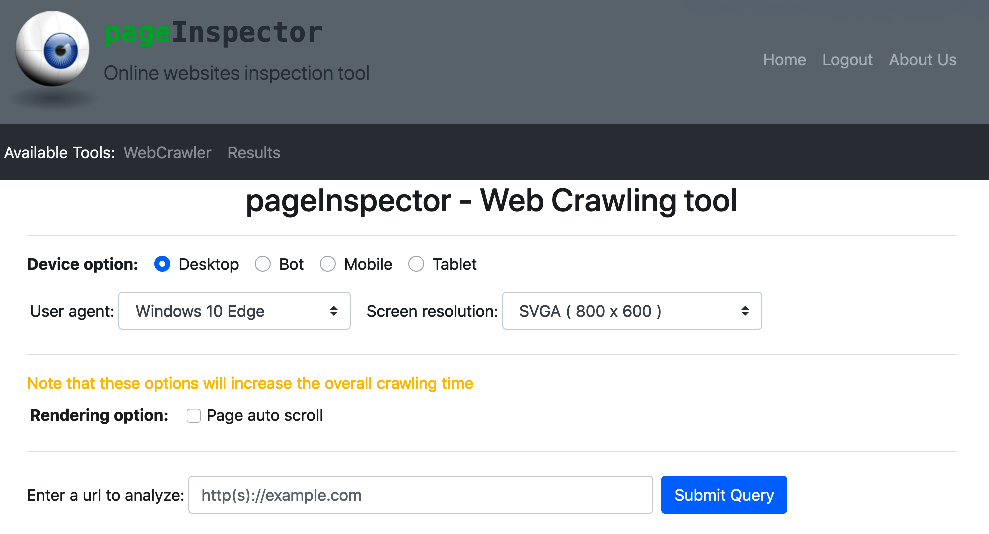
1. Web crawler interface
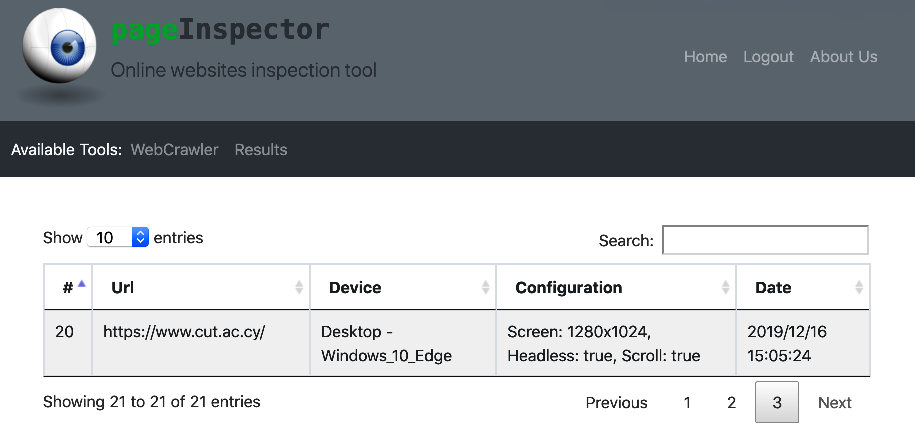
2. Results table
3. Result page
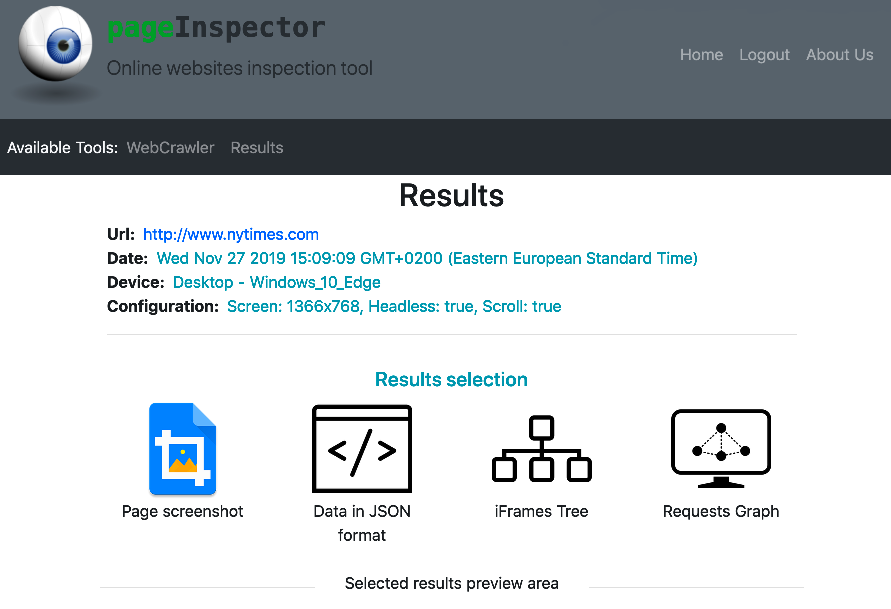
The result page allows the user to interact with the web-page data either by searching directly the raw data, visualized as a JSON Object, or by using the different visual representations of the web-page rendering information in the form of graphs.
The four main results are the following:
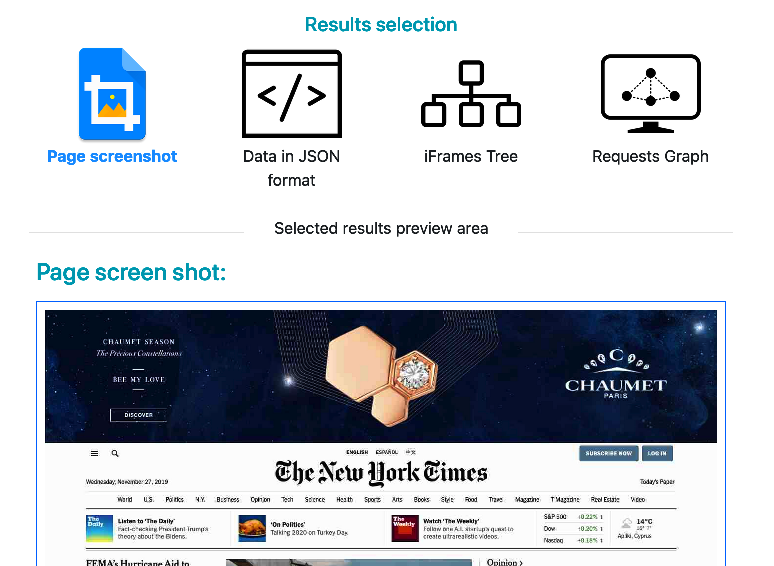
- Screenshot of the web-page for visual inspection.
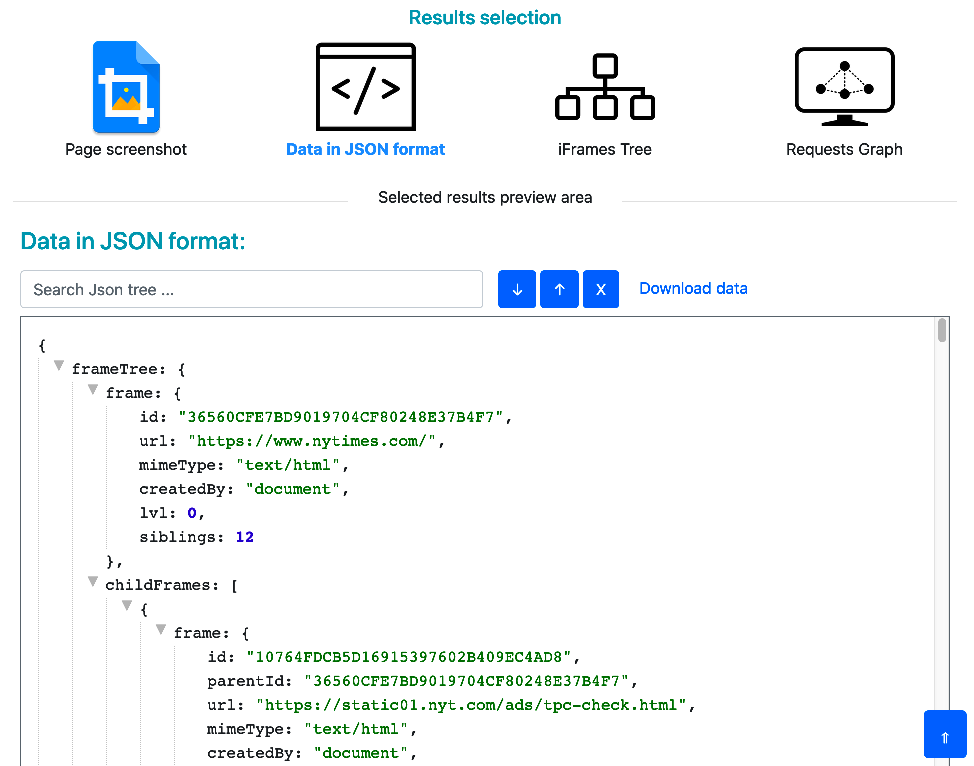
- The raw data in JSON format, also available to download.
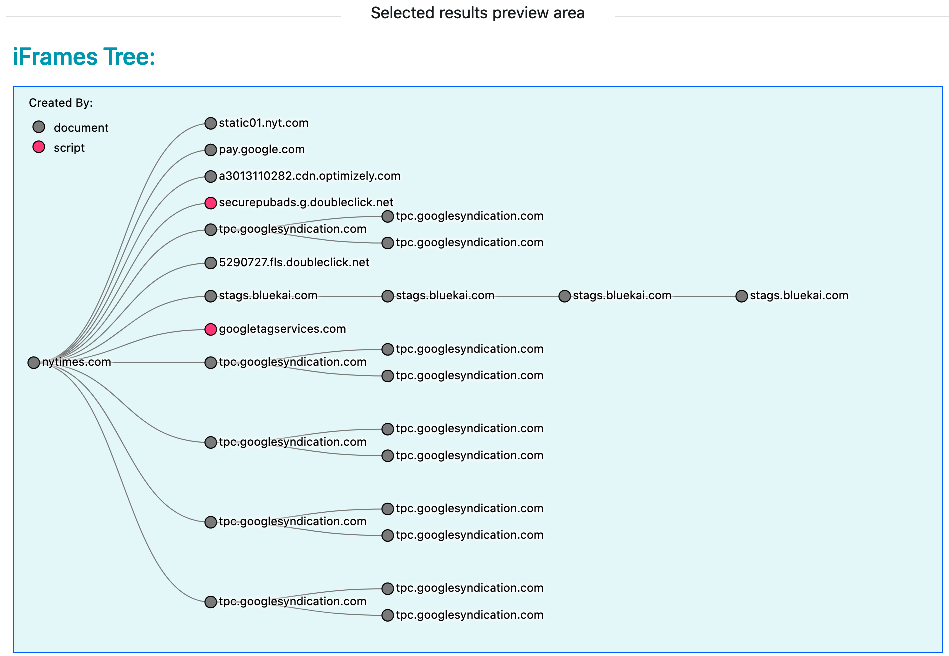
- The web-page iFrames tree visualization.
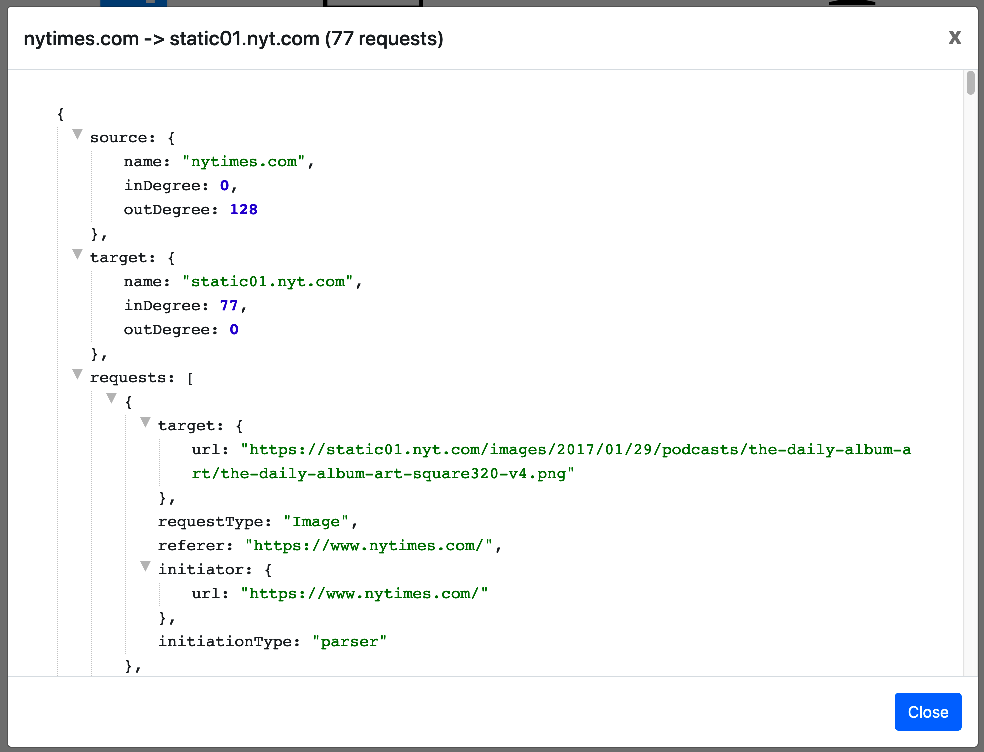
- The visualization of all http(s) requests of the web-page as a directed graph.
3.1. Page screenshot
3.2. Page requests in JSON format
3.3.1. Page iFrames tree
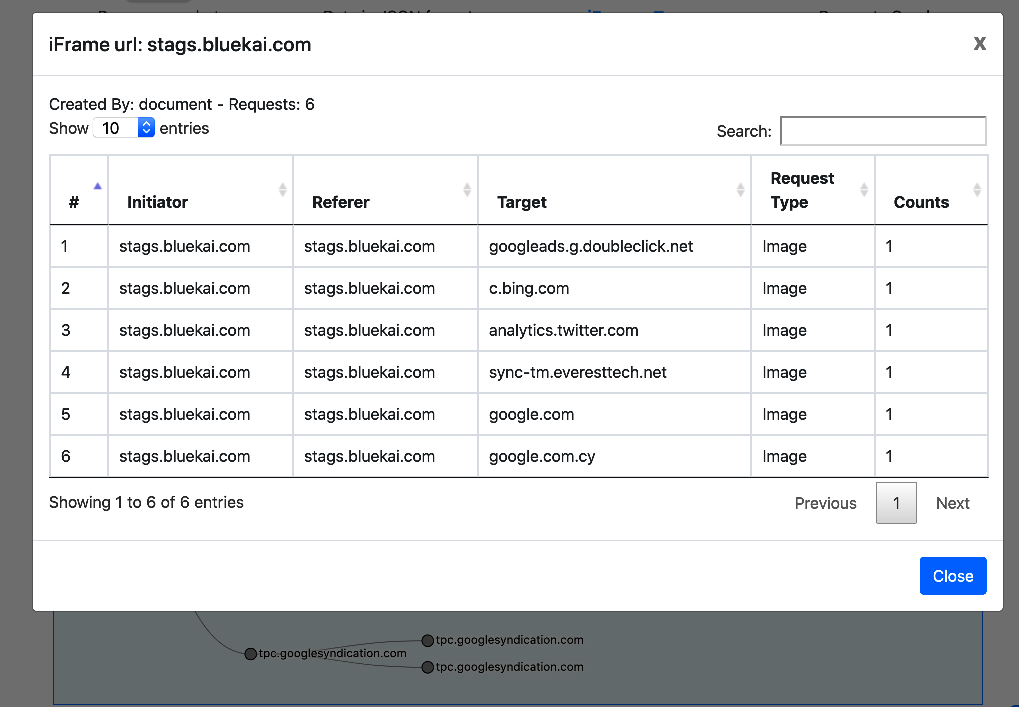
3.3.2. Page iFrames tree popup
3.4.1 Page requests graph
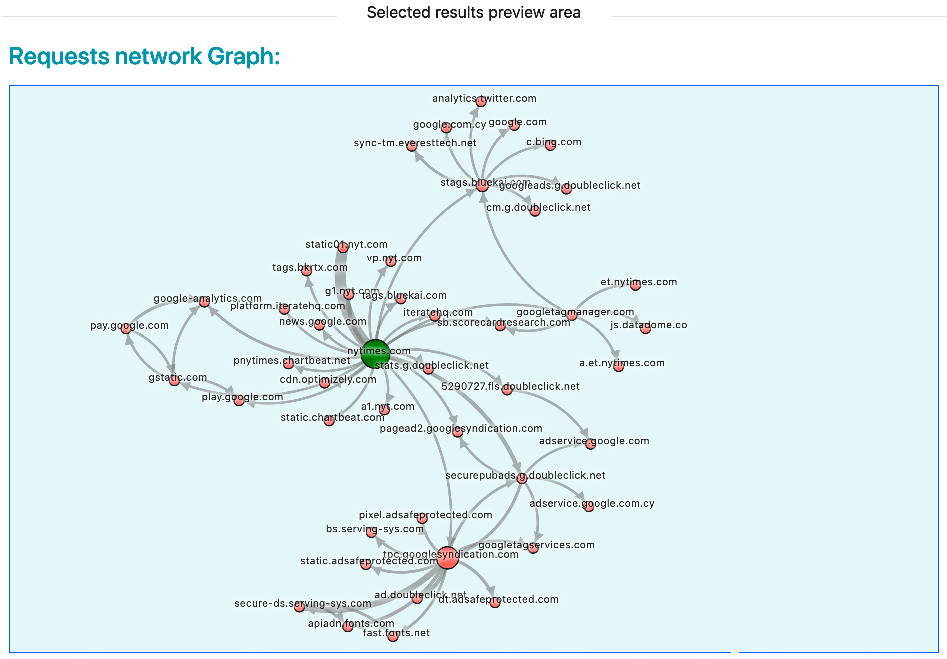
3.4.2. Page requests graph popup